
Agilité
Je pense donc je blogue
25/07/2022
Eric Dasse
“87% des projets de machine learning ne parviennent pas à atteindre la production”
En d’autres termes, ils ne parviennent pas à aller plus loin que la phase de test voire de développement.
Vous avez peut-être déjà vu cette fameuse statistique du blog VentureBeat passer il y a quelques années. Elle a sans aucun doute évolué avec le temps, mais toujours est-il que de bien des manières, elle est justifiée.
En effet, les projets de machine learning (ML pour les copaings) ont des spécificités en termes d’industrialisation qui ont perturbé plus d’une entreprise ! Dans beaucoup d’entre elles, même aujourd’hui, industrialiser un projet de machine learning donne l’impression de se heurter à un mur.
Les difficultés ne sont d’ailleurs pas que techniques. Elles sont tout autant humaines et organisationnelles. Mais la bonne nouvelle est que l’industrialisation de projets de ML est un sujet qui a beaucoup mûri au fil des années. Ainsi, pour faciliter ce processus tout en prenant en compte les spécificités des projets ML, un ensemble de pratiques issues de la philosophie DevOps ont fait leurs apparitions il y a quelques années. Ces pratiques portent collectivement le nom de MLOps.
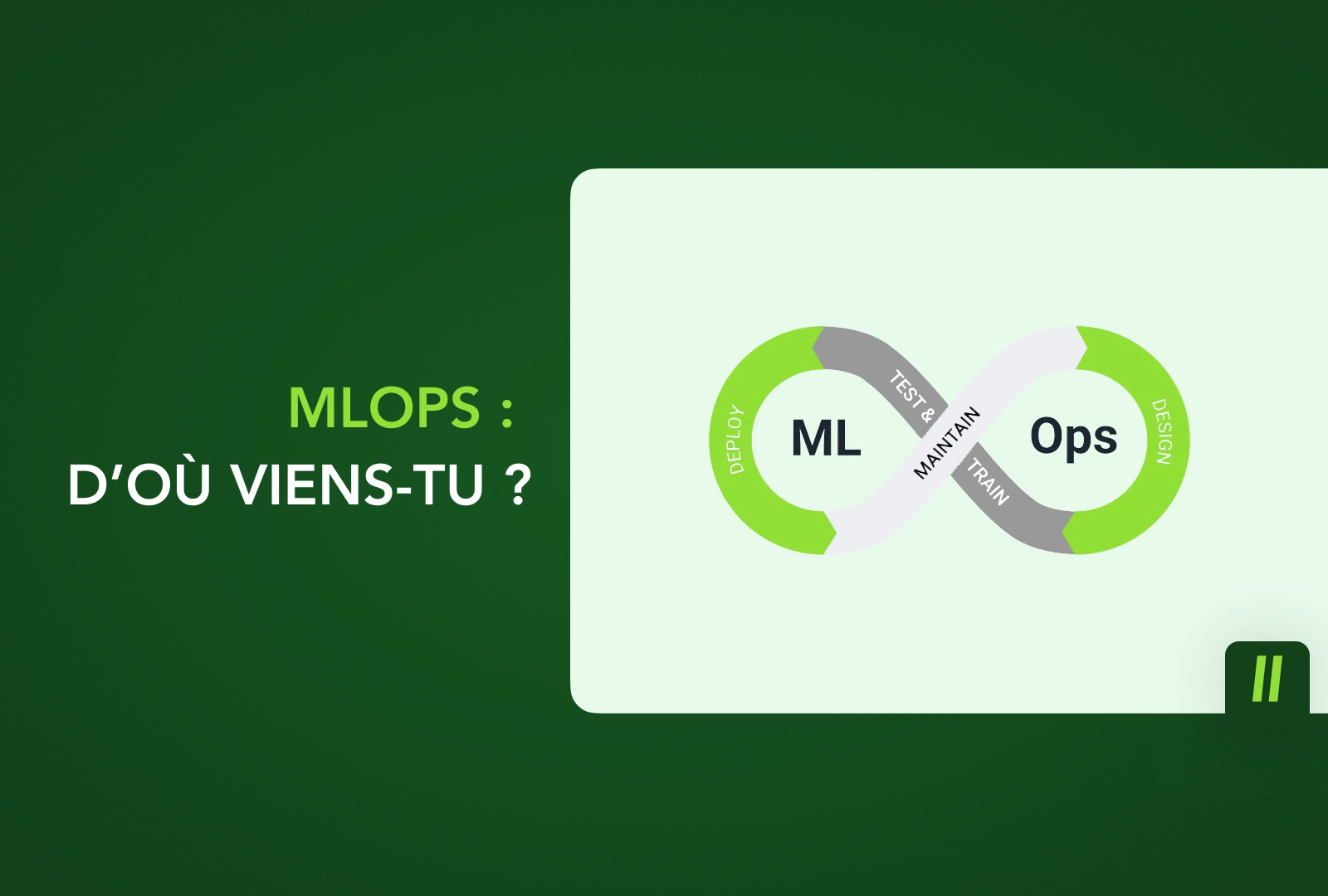
Le MLOps (Machine Learning Operations) est un ensemble de pratiques pour concevoir, déployer et maintenir des modèles de machine learning en production d’une manière ininterrompue, fiable et efficiente. C’est une extension du DevOps appliquée spécifiquement à la gestion des modèles de machine learning.
Dans cet article, nous allons donner un peu de contexte sur les difficultés inhérentes à la mise en production des modèles de machine learning et sur ce que le MLOps apporte pour y faire face.
Les raisons qui ont conduit à l’avènement du MLOps sont assez similaires à celles qui ont conduit au mouvement DevOps dans le cas du développement logiciel traditionnel, mais avec quelques ingrédients supplémentaires…
D’ailleurs, vous savez comment le mouvement DevOps est né ?
Dans le contexte d’entreprise, la mise en production d’un logiciel nécessite souvent la collaboration de deux branches de compétences IT : les développeurs et les ingénieurs d’opérations (les Ops pour les intimes). Cependant, ces deux branches ont des objectifs en apparence antagonistes : les développeurs ont besoin de pouvoir modifier régulièrement les logiciels, notamment pour y apporter des améliorations ou corriger des bugs, tandis que les Ops sont chargés d’assurer la stabilité des logiciels. Cela a donc naturellement fini par mener à des tensions voire des conflits dans plusieurs entreprises entre les équipes de développement et les équipes Ops, érigeant un mur mental entre eux qu’on appelle le mur de la confusion. C’est un phénomène qui était particulièrement prononcé il y a un peu plus d’une dizaine d’années, bien qu’il persiste dans beaucoup d’entreprises aujourd’hui encore.
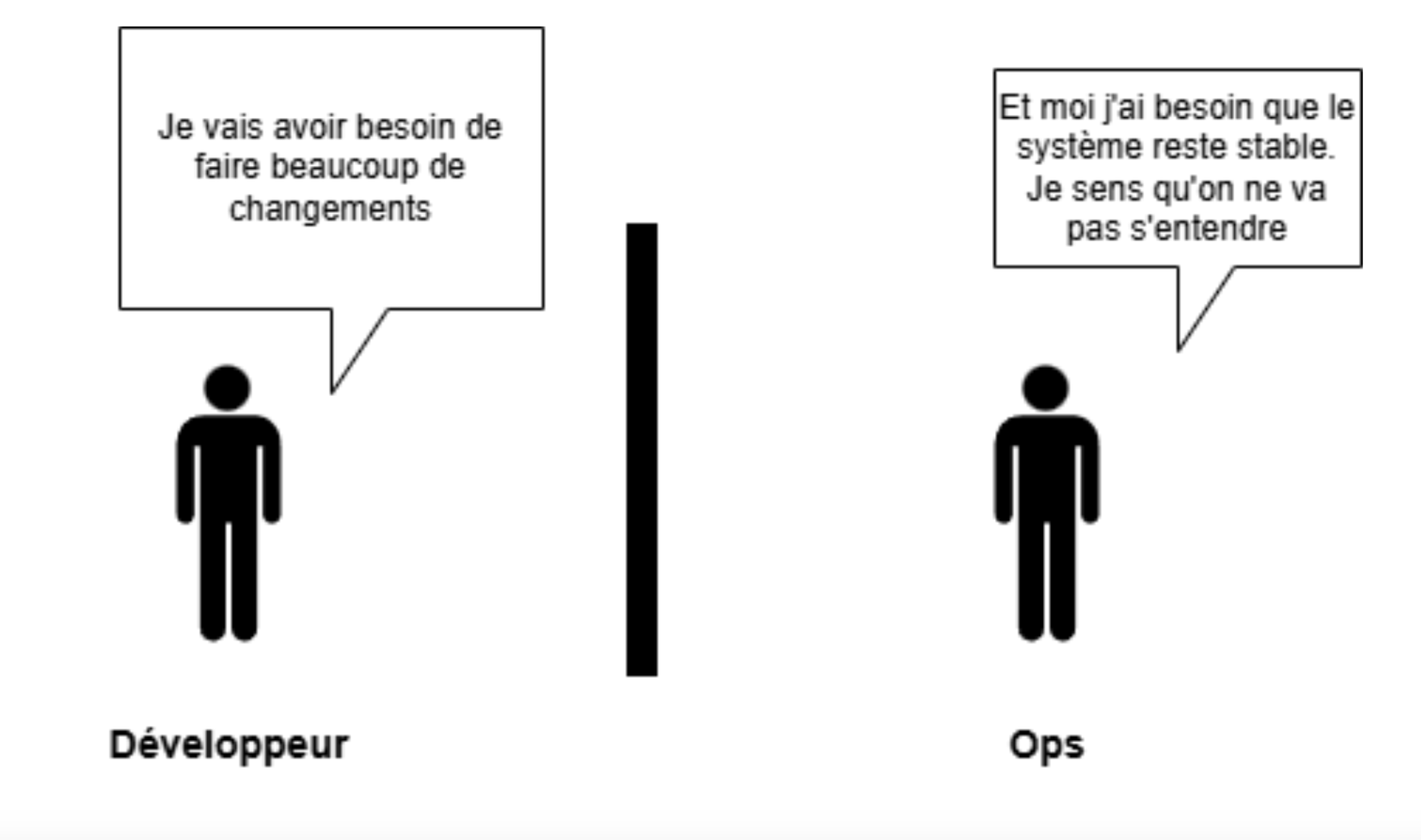

La philosophie DevOps ainsi que les pratiques qui l’accompagnent proposent de nombreux moyens de fluidifier la collaboration de ces deux branches de compétences. Le DevOps est avant tout une culture. Une culture de co-construction et de responsabilité partagée entre les développements et les opérations pour les produits qu’ils créent et maintiennent.
Beaucoup de pratiques facilitent cette culture, notamment le versioning de code, le shift left avec la CI/CD, la conteneurisation (à l’aide de Docker et K8s par exemple) ou encore l’infrastructure as code (par exemple avec Terraform).
Ces pratiques ont énormément apporté à beaucoup d’équipes, qu’elles fassent du développement plus conventionnel ou même du machine learning d’ailleurs.
D’une manière similaire au développement logiciel usuel, le processus de développement et de mise en production d’un modèle de machine learning fait également intervenir différentes branches de compétence. Par contre, un peu plus de branches sont impliquées dans le cycle de vie classique d’un modèle, typiquement :
Note : Sur un projet donné, une même personne peut consciemment ou non concentrer plusieurs de ces branches de compétence. Toutefois, pour une meilleure compréhension de la problématique que je m’apprête à présenter, il reste important de les séparer mentalement.
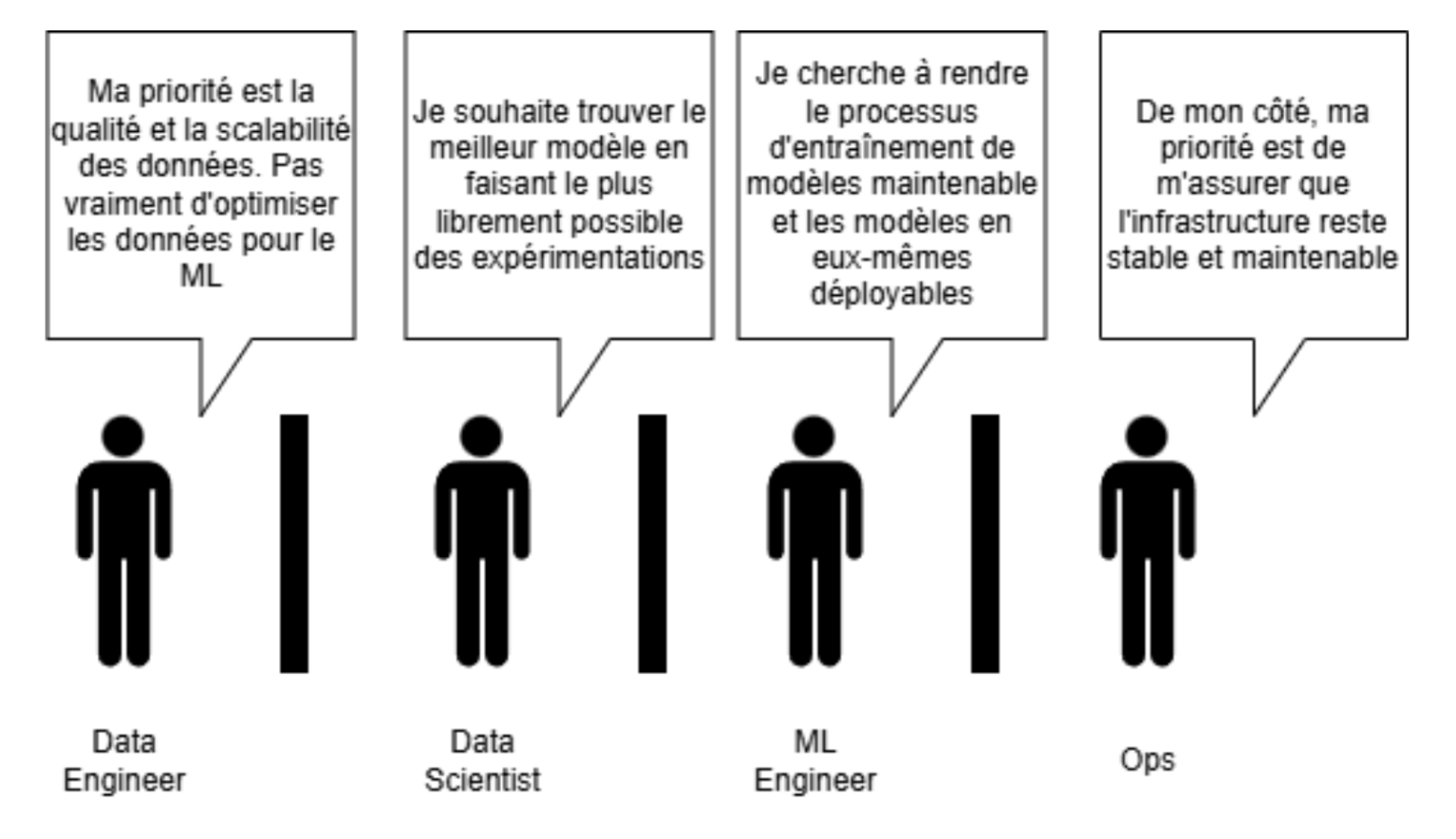
Ces branches de compétence ont chacune leurs propres attributions et surtout leurs propres priorités
| Data Engineering | Data Science | ML Engineering | Ops | |
| Responsabilité | Acquérir et mettre à disposition des données dans un format adéquat pour la partie prenante concernée | Explorer les données, déterminer ce qu’on peut en tirer et dans plusieurs cas bien entendu, faire des expérimentations de modèles de ML pouvant être produits à partir de ces données | Parfait complément à la data science, c’est une forme d’ingénierie logicielle dans laquelle on automatise et met à l’échelle l’entraînement des modèles de ML. Touche également au développement de solutions intelligentes basées sur ces modèles, par exemple en les intégrant dans des APIs ou des applications | Gérer et maintenir l’infrastructure permettant de déployer et faire tourner un modèle en production (ou toute autre composante logicielle en général) |
| Priorité (dans un contexte ML) | Qualité et scalabilité des données.
N’est pas forcément concerné par l’optimisation des données pour le ML |
Recherche du meilleur modèle possible.
Quitte à favoriser l’expérimentation à l’efficacité |
Cherche un équilibre entre performance du modèle et déployabilité | Stabilité et maintenabilité de l’infrastructure |
Qui plus est, en général, il y a souvent des passages de relai. Par exemple :
Un Data Engineer peut fournir à un Data Scientist les données qu’il a besoin d’explorer pour en déduire comment les exploiter et quels modèles utiliser. Ensuite, une ML Engineer peut se baser sur les expérimentations du Data Scientist en question pour mettre en place un pipeline d’entraînement de modèle qui soit automatisé et mis à l’échelle. Qui plus est, pour travailler, les 3 rôles précédents ont besoin de ressources computationnelles et doivent donc collaborer avec des Ops garants de l’infrastructure.
Ainsi, si dans le cas du développement logiciel habituel un mur de confusion peut se créer entre développement et opérations, il peut également se former entre chacun des rôles mentionnés précédemment en raison de leurs priorités différentes dans le processus de mise en place d’un modèle.
Cela donne des passages de relais qui peuvent être … compliqués pour le dire simplement.
Ceci dit, même si leurs priorités sont différentes, il est important de se rappeler qu’elles ne sont pas antagonistes. Ils ont un but commun qui est la construction d’un produit ML. Et c’est là tout l’enjeu de la culture MLOps : réduire les frictions et faciliter la co-construction.
Les pratiques MLOps approchent le développement et la mise en production de modèles de ML d’une manière assez analogue au développement logiciel. En d’autres termes, afin que le développement et le déploiement en production des modèles de machine learning soient continus, fiables et efficaces, les pratiques MLOps permettent de rendre différentes étapes du workflow répétables et automatisées.
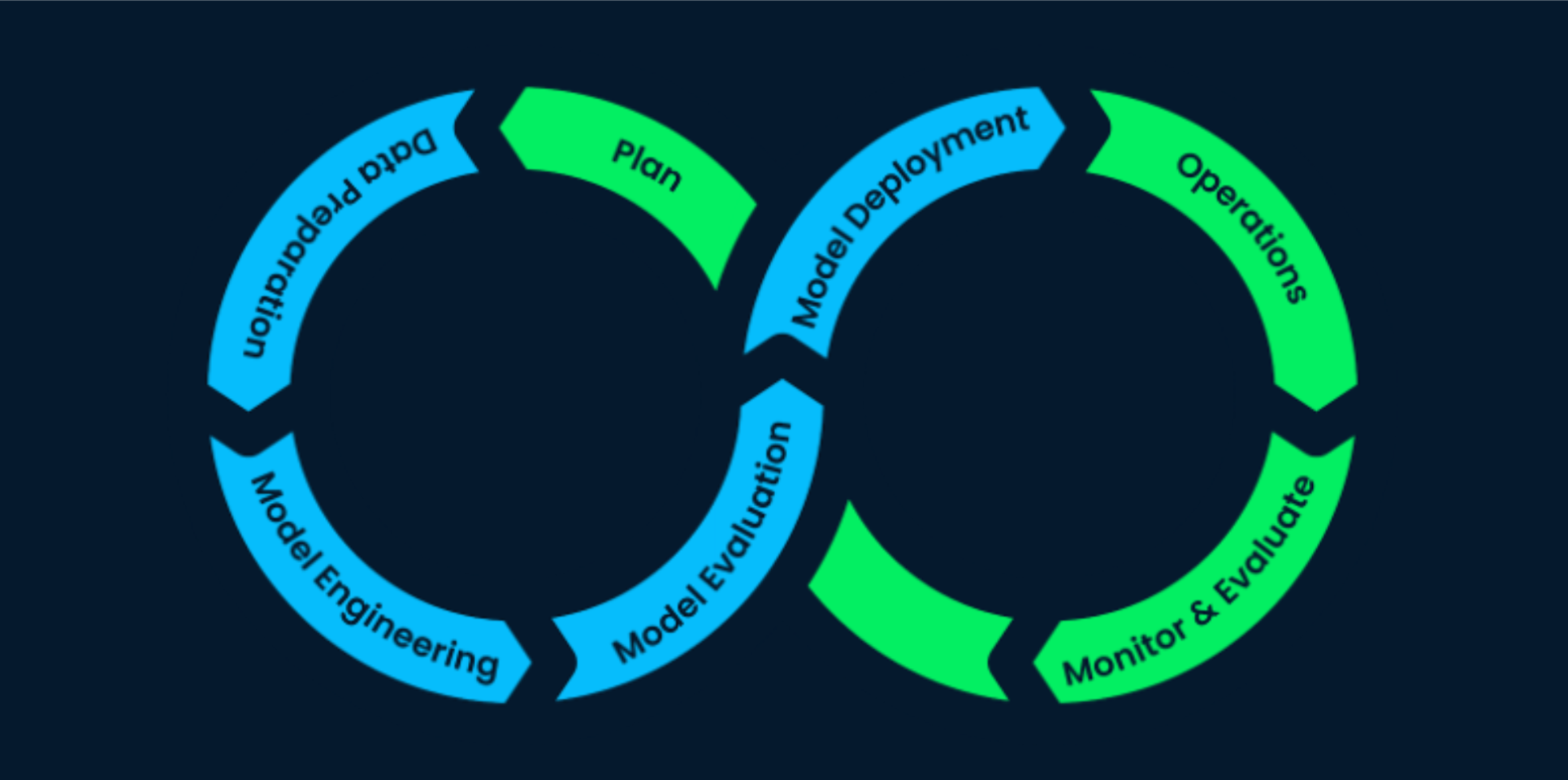
Source : DataCamp
En effet, des processus répétables et traçables facilitent la collaboration. Ainsi, par essence, beaucoup de pratiques et d’outils DevOps se retranscrivent bien dans des projets de ML (ex. CI/CD, conteneurisation, versioning de code, Infrastructure as Code, etc.).
De même, la lisibilité et la maintenabilité du code restent des points importants pour faciliter la collaboration dans cette culture.
Cependant, sur certains points, le MLOps se distingue nettement de l’approche DevOps, par exemple :
Le point crucial à retenir est que la philosophie MLOps se veut prendre les besoins spécifiques du processus de développement et de déploiement d’un produit ML. De ce fait, en plus de certaines pratiques et outils DevOps qui restent tout aussi pertinents, de nouvelles pratiques et outils sont apparus (ou ont été adaptés) pour faciliter cette culture.
D’une manière analogue au DevOps, le MLOps est avant une culture de co-construction et de responsabilité partagée pour le produit ML à développer et maintenir. Et comme mentionné plus haut, c’est une culture qui prend en compte les spécificités du contexte ML.
Afin de matérialiser concrètement les intentions de cette culture, de nouvelles pratiques ont vu le jour, parmi lesquelles :
Et également avec de nouveaux outils comme MLFlow, Kedro, DVC ou Kubeflow.
D’ailleurs, je vous propose d’approfondir davantage ces concepts dans de prochains articles. Restez attentifs !
Les projets de ML font collaborer différents rôles IT avec des natures et des priorités qui peuvent empiéter les unes sur les autres si elles ne sont pas bien encadrées. Qui plus est, même d’un point de vue technique, ces projets posent des problématiques qui leur sont bien spécifiques. Les pratiques MLOps adaptent donc la philosophie DevOps au contexte des projets de ML pour faciliter la collaboration entre les rôles impliqués, réduire le time-to-market des projets de ML, améliorer leur fiabilité et surtout faciliter la réponse aux changements et imprévus. Cette manière de travailler permet aux différents rôles de prendre en compte directement ou indirectement les contraintes des uns et des autres afin de fluidifier les processus de développement et de déploiement de modèles.
J’espère qu’à la lecture de cet article vous avez une meilleure vue d’ensemble de ce qu’est le MLOps et de sa manière de faciliter le développement et la mise en production de projets de ML. Nous approfondirons le sujet dans des prochains articles, restez branchés 😉
