Pour être un bon micro-développeur, vous allez devoir vous familiariser avec certaines notions. La principale difficulté réside dans les communications interservices. Voici quelques recommandations pour mener à bien votre mission:
- Eviter à tout prix les intégrations par base de données. Si plusieurs microservices communiquent avec la même base de données, vous n’aurez plus du tout d’indépendance. Chaque modification de schéma impliquera des modifications de tous les µservices y étant liés.
- Privilégiez les appels REST sur les mécanismes de RPC (Remote Procedure Call). Les intégrations de services via REST sur HTTP sont un bon choix pour débuter.
- N’exposez pas les détails de vos implémentations dans vos APIs, gardez vos APIs technologiquement agnostiques. Il faut éviter les technologies d’intégration qui imposent la technologie ou le langage à utiliser.
- Un microservice doit être simple d’utilisation.
- Préférez toujours la chorégraphie à l’orchestration de service. Prenons un exemple simple : lors d’une création de compte sur mon site de e-commerce, je souhaite créditer des points de fidélité au client, lui envoyer un cadeau par la poste et lui envoyer un mail de bienvenue.
L’orchestration consisterait en :
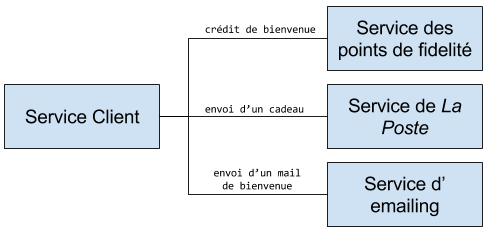
La chorégraphie en :

- Optez pour une collaboration asynchrone par évènement. Les différents brokers de message comme Apache QPid, OpenAMQ, Windows Azure Service Bus ou encore RabbitMQ vont vous permettre de publier et consommer des évènements assez simplement. Cependant il faut savoir qu’il y aura un coût supplémentaire pour la mise en place et la maintenance d’une telle solution.
- Publiez tous vos messages sur un seul bus, lisible par tout le monde.
- Il faut intégrer dans votre travail le fait que chaque appel à un microservice peut échouer. Il va donc falloir être beaucoup plus attentif à la gestion d’erreur.
- Privilégiez toujours l’autonomie sur l’autorité.
Un service autonome doit pouvoir assurer sa responsabilité seul. Dans le cas d’une récupération de donnée une configuration en autonomie pourrait être:
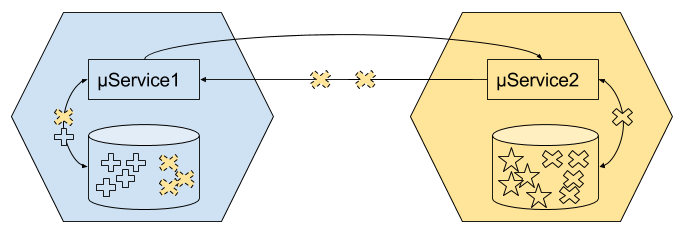
Alors qu’une configuration autoritaire serait :
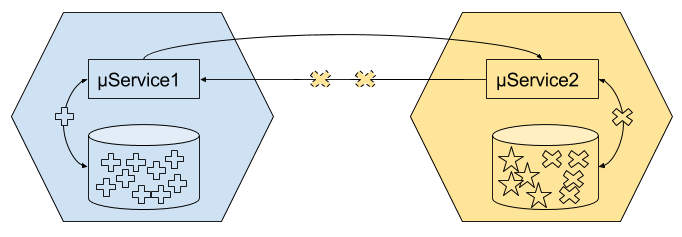
Lorsqu’un service a l’autorité sur un autre, les données sont toujours à jour, alors que lorsqu’il est autonome, il existe une latence. Cependant dans un laps de temps plus ou moins court, les données seront mises à jour. Notez tout de même que pour rester autonome la gestion par évènement est parfaite.
- Prenez en compte que les données ne sont pas tout le temps à jour dans des systèmes distribués, on parle de “eventual consistency”.
- Acceptez la panne de vos services, mais prévenez haut et fort tous leurs utilisateurs.
Les développeurs de Netfilx sont partis du principe que la panne surviendra forcément. Ils ont créé un outil la provocant volontairement pour tester en prod la résilience de leur système, le Chaos Monkey. Ils ont également mis à disposition une librairie très utile pour gérer les interactions dans un système distribué : Hystrix.
- Pensez à des mécanismes de compensation pour contrer les problèmes d’eventual consistency.
- Supervisez. Le monitoring va devenir beaucoup plus complexe dans une architecture distribuée.
- Monitorez les temps de réponse utilisateurs. Le RUM (Real User Monitoring) est un outil idéal, il existe des solutions clés en main sur le marché comme New Relic, mPulse de SOASTA ou encore pingdom.
- Utilisez des Time Series Database qui permettent de stocker des métriques à intervalle régulier, comme InfluxDB (rétrocompatible avec Graphite) ou OpenTSDB.
- Traquez toutes les communications, Hystrix fournit ce service nativement.
- Standardisez vos logs et trouvez un moyen de les agréger.
- Utilisez des identifiants pour les différentes requêtes (corrélation ids).
- Formez des équipes pluridisciplinaires pour être autonome.
- Découpez finement mais intelligemment vos services. Les microservices doivent pouvoir être réécrits intégralement en peu de temps. De ce fait, ils doivent être de très petite taille et compréhensibles rapidement.
- Renseignez-vous sur l’offre du marché. Il existe plusieurs outils qui vous aideront, en voici une liste, non exhaustive bien sûr :
- Vert.x : Boîte à outil polyglotte facilitant l’implémentation d’application réactive. Utilisé notamment par RedHat, Bosch, Cyanogen, Groupon…
- Hystrix : Librairie (portée dans plusieurs langages) développée par les ingénieurs de Netflix permettant d’être tolérant à la panne facilement et notamment d’éviter les effets domino.
- Docker : docker va permettre de conteneuriser vos microservices, de les tester et déployer plus facilement
- Apache Kafka vous aidera si vous partez sur une solution event-sourcing
- Apache Flume vous permettra de collecter et agréger les logs de vos différents services
- Microsoft Azure Service Fabric est une solution complète pour orchestrer des services distribués.
Ces différentes recommandations vous serviront certainement à la mise en place d’une architecture en microservice. Mais vous l’aurez compris, ceci est une philosophie à adopter et non pas une suite d’outils à utiliser. Ne tombez pas dans le piège consistant à vouloir profiter à tout prix de tous les avantages d’une telle architecture. Restez pragmatique en vous focalisant sur les points qui répondent à vos problématiques.