
Articles
Stratégie IA
07/04/2026
Baptiste Mace


07/04/2026
Baptiste Mace

04/03/2026
Dorra BARTAGUIZ

09/02/2026
Alexandra Courtiol

06/11/2025
Vincent BAUCHART
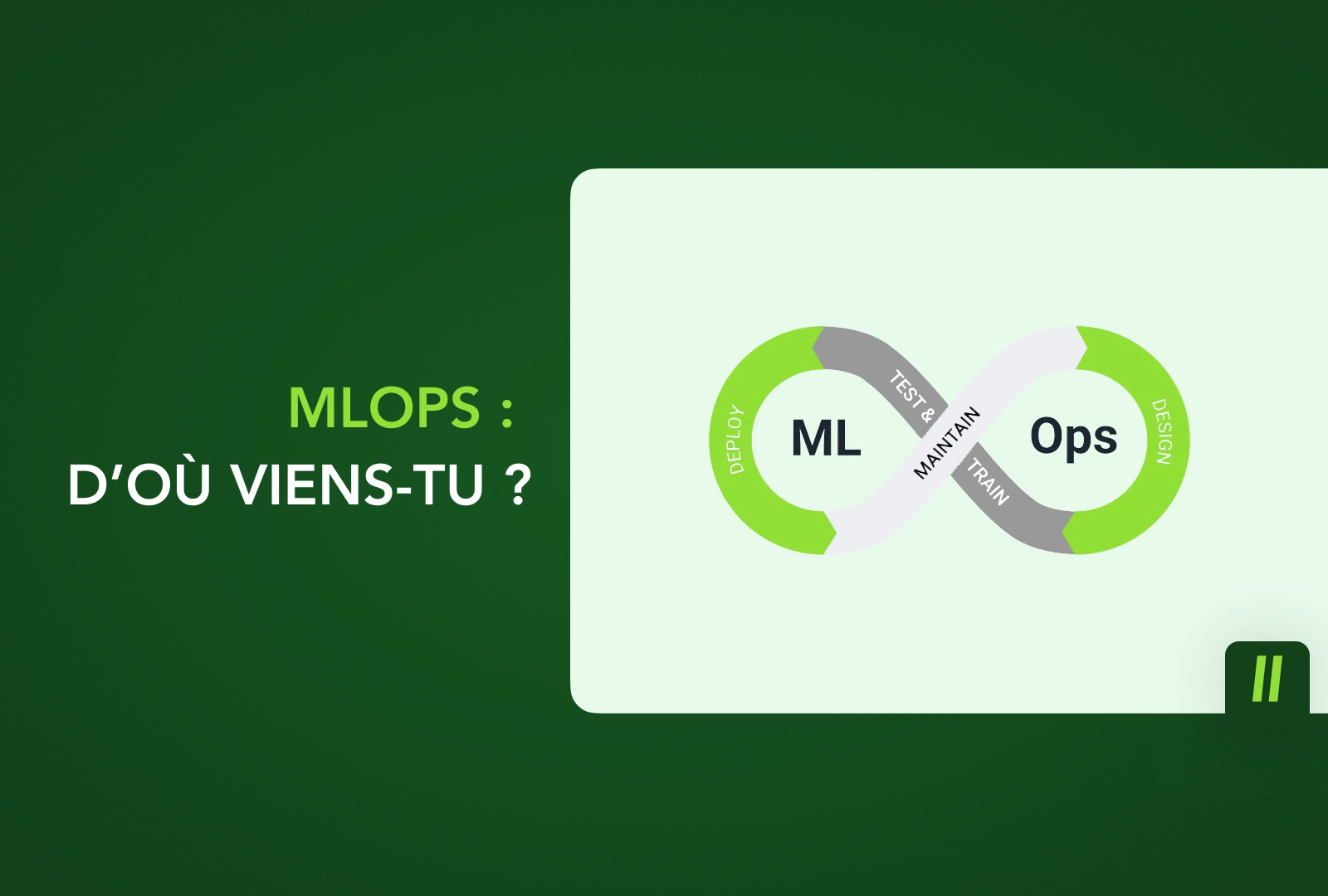
04/07/2025
Eric Dasse

26/06/2025
Sylvain YVONNEAU

23/06/2025
Cyrille Martraire

14/05/2025
Alexis Nguyen-Goument

13/05/2025
Arnaud Lacroix

07/05/2025
Alexandra Courtiol

05/05/2025
Baptiste Mace

28/04/2025